
Blog Post: Yari
Date: June 25th, 2026
HireVue is not a lie detector in the old school, fluorescent lit of “did you steal the company stapler?” sense. There’s no wires. No sweating palms hooked up to a machine, nor dramatic examiner sitting across from you like a rejected character from Law & Order: Corporate Compliance Unit. But culturally, HireVue style hiring assessments have started to feel like the modern workplace’s algorithmic polygraph: a system that takes nervous human behavior, extracts patterns from it, and then sells those patterns back as insight. That is where the problem begins.
The old lie detector was built on a shaky premise: stress equals deception. Your heart rate jumps, your voice changes, your body reacts, and suddenly the machine is treated like it has unlocked your inner truth. Except stress is not truth. Stress is stress. It can mean fear, pressure, trauma, neurodivergence, language processing, disability, or simply the soul crushing realization that you are interviewing for a job that requires “entry level experience” and five years of SQL.
HireVue style systems raise a similar concern. They may not be asking, “Are you lying?” But they can still participate in the similar cultural fantasy: that messy human behavior can be converted into clean corporate truth. A candidate sitting alone in front of a webcam is not in a neutral environment, or even a natural one. They’re being timed, recorded, scored, and evaluated by a system they cannot fully see or even measure. Their voice may shake because they are nervous, their pauses may mean thoughtfulness, their flat affect may be disability related. Their speech rhythm may reflect culture, language background, anxiety, a motor condition, or simply a bad Wi-Fi connection trying to ruin their life like it has a personal vendetta. But once those behaviors enter a hiring system, they risk becoming data points. A pause becomes “low confidence”, a different speech pattern becomes “poor communication”, a lack of eye contact becomes “weak presence” and a nervous tone becomes “risk.” That isn’t necessarily measurement.
To be fair, companies have every right to want better hiring data, but hiring has also always used imperfect signals: resumes, interviews, references, work samples, personality tests, and case studies. The issue is not data itself. The issue is what kind of data gets collected, how it gets translated into a score, and whether candidates are given enough transparency to challenge or understand that result.
A good hiring metric should be explainable and job related. Can the candidate write the SQL query? Can they analyze the dataset? Can they explain the product tradeoff? Can they handle the client conversation? Can they build the model, debug the dashboard, interpret the market, or prioritize the roadmap? Those are job signals, and very measurable metrics, although they too care imperfection.
Scoring someone’s tone, rhythm, expression, timing, or behavioral presentation risks measuring something else entirely: how well they perform employability under surveillance, and comfort with surveillance is not a job skill unless you’re in the CIA. That’s especially dangerous for disabled candidates, neurodivergent candidates, non-native English speakers, low income candidates, and nervous applicants. The system may not explicitly say, “Reject people with disabilities” or “Penalize anxious people.” Bias rarely arrives wearing a villain cape, instead it shows up in the transform step. It shows up when a model learns what “strong communication” looks like from a narrow slice of people and quietly treats everyone else as deviation. That is how difference becomes deficiency.
A candidate with autism may avoid eye contact or process questions differently. A candidate with a speech disability may pause more often, repeat words, or speak with a different rhythm. A candidate with ADHD may appear less linear. A candidate with anxiety may sound tense because, shocking plot twist, interviews are stressful. None of that means they are unqualified. It means they are human, and humans are inconveniently hard to compress into a dashboard, many psychology studies are even difficult to replicate because of variances.
This is the part that should make us uncomfortable. In a normal interview, a good human interviewer can notice context. They can say, “This person seemed nervous at first, but their actual answer was strong.” They can clarify, follow up, accommodate, and judge the substance of the work. A rigid automated scoring process can make that harder, especially if it’s used early in the funnel before a person ever gets a real chance.
Support tools can become gatekeepers very quickly. Once a system decides who advances, it’s no longer just helping hiring teams, it’s shaping the labor market. That is why the “next lie detector” comparison matters. Not because HireVue is literally a polygraph, but because both systems share the same temptation: the belief that hidden truth can be extracted from visible behavior. The polygraph wanted to read guilt through physiology, while algorithmic hiring wants to read competence through performative data. Same movie, new streaming platform, and like every reboot nobody asked for, the branding is cleaner, the interface is sleeker, and the underlying plot still needs work.
The ethical issue isn’t that companies use technology. Technology can absolutely improve hiring when it is used responsibly. Structured interviews, transparent rubrics, validated work samples, accessible assessments, and consistent scoring can reduce bias compared with chaotic “vibe based” hiring. Nobody’s arguing that the old system was a civil rights utopia. Traditional interviews have plenty of bias. Some hiring managers treat “culture fit” like astrology with a LinkedIn account, but replacing human bias with algorithmic opacity isn’t progress. It’s just moving the bias into a black box and giving it a product demo.
The easiest way to understand HireVue style AI hiring is through an ETL pipeline: Extract, Transform, Load.
Underneath that clean workflow is the actual ethical issue: the system takes messy human behavior, cleans it until it looks scientific, and loads it into a recruiter dashboard as if uncertainty has been solved, but it has not been solved, it’s just been formatted.
Step 1: Extract & What the system collects
In the extract phase, the candidate records a video interview. The system may collect the transcript, response length, timing, word choice, pauses, speech patterns, and other metadata. Historically, some tools in the market also analyzed visual features like facial expressions or gaze direction, though HireVue later discontinued facial analysis.
The data might look something like this:
candidate_video = load_video("candidate_interview.mp4")candidate_audio = extract_audio(candidate_video)candidate_transcript = speech_to_text(candidate_audio)metadata = { "role": "Data Analyst", "question_id": "Q3", "response_time_seconds": get_response_time(candidate_video), "recording_quality": assess_audio_video_quality(candidate_video), "internet_stability": estimate_connection_quality(candidate_video)}audio_features = { "speech_rate": calculate_words_per_minute(candidate_transcript, candidate_audio), "pause_frequency": count_pauses(candidate_audio), "pause_duration_avg": average_pause_length(candidate_audio), "volume_variability": measure_volume_variability(candidate_audio), "pitch_variability": measure_pitch_variability(candidate_audio)}language_features = { "keyword_match": score_role_keywords(candidate_transcript, role="Data Analyst"), "answer_structure": score_star_format(candidate_transcript), "clarity_score": score_clarity(candidate_transcript), "sentiment_score": estimate_sentiment(candidate_transcript), "filler_word_count": count_filler_words(candidate_transcript)}
On paper, this looks clean, as the system is simply collecting data but this is where the first problem begins: the data isn’t neutral just because it’s digital.
A pause isn’t just a pause. It can mean anxiety, deep thinking, disability, translation, trauma response, low bandwidth, or a candidate trying not to say, “This question was clearly written by someone who has never done this job.”
A shaky voice can mean nervousness. It can also mean a speech disability, illness, exhaustion, or the fact that the candidate is doing the interview in their kitchen while their neighbor’s dog is auditioning for The Voice.
The extraction step pretends the candidate is being measured in a lab. In reality, they’re being measured inside a situation. That distinction matters.
Failure at this stage: The System Extracts Context, then Pretends It Extracted Character
The first black-box problem is that the system gathers behavioral signals without fully knowing what caused them. It may know that the candidate paused for three seconds.
It doesn’t know why. But later in the pipeline, that “why” may get quietly replaced by a corporate label like confidence, communication, professionalism, or engagement. That is how the black box starts growing. The system collects ambiguous human behavior, then carries that ambiguity forward as if it were clean data. The candidate isn’t just answering questions, they’re being turned into extractable behavior.
Step 2: Transform & Where human behavior becomes cooperate meaning
The transform phase is where the magic trick happens. This is the step where raw features are normalized, weighted, and mapped onto employer-facing categories.
raw_features = { **metadata, **audio_features, **language_features}normalized_features = normalize_features(raw_features)competency_scores = { "communication": weighted_sum({ "clarity_score": normalized_features["clarity_score"], "answer_structure": normalized_features["answer_structure"], "speech_rate": normalized_features["speech_rate"], "filler_word_count": inverse(normalized_features["filler_word_count"]) }), "confidence": weighted_sum({ "pause_frequency": inverse(normalized_features["pause_frequency"]), "pause_duration_avg": inverse(normalized_features["pause_duration_avg"]), "volume_variability": normalized_features["volume_variability"], "pitch_variability": normalized_features["pitch_variability"] }), "job_relevance": weighted_sum({ "keyword_match": normalized_features["keyword_match"], "answer_structure": normalized_features["answer_structure"], "clarity_score": normalized_features["clarity_score"] })}
This is the most dangerous part of the pipeline as it looks mathematical, but it’s also interpretive. The code doesn’t simply “find confidence.” It defines confidence through proxies. Fewer pauses equals more confidence, steady volume equals professionalism and certain keywords equal job relevance. Maybe a STAR format answer equals stronger communication, but here is the problem: those are assumptions.
A candidate can be brilliant and pause often, confident but soft spoken, neurodivergent but with an unstructured format, a non-native English speaking that is still exceptional at the job. A candidate can use fewer corporate buzzwords as they actually understand the work instead of reciting LinkedIn soup.
The transform step is where difference gets translated into deficiency. It’s also where the system becomes less explainable. The original data was already ambiguous. Now that ambiguity is being compressed into categories that sound objective like: Communication: 62, Confidence: 48, Job relevance: 71. The numbers look precise, but precision isn’t the same as truth. A Magic 8 Ball with decimal points is still just a Magic 8 Ball.
Failure at this stage: The Model Turns Bias into Math
The transform phase expands the black box as it hides human judgment inside technical choices.
Who decided which features matter? When should pause frequency affect confidence? What “good communication”sounds like? What training data represented everyone? And who checked whether disabled candidates, anxious candidates, non-native English speakers, or working class candidates were being penalized?
These aren’t just technical questions. They’re ethical questions.
Once those decisions are buried inside a model, they become harder to challenge. The company can point to the score. The recruiter can point to the dashboard. The vendor can point to the audit. But the candidate is left with the worst customer service experience in capitalism: rejected by a system they cannot see, using criteria they cannot inspect, for reasons they cannot appeal.
That is not transparency, it’s a velvet rope with an algorithm.
Step 3: Load & Where the score becomes a hiring decision
In the load phase, the system sends the output to a recruiter dashboard. The messy interview becomes a clean report.
final_candidate_score = weighted_sum({"communication": competency_scores["communication"], "confidence": competency_scores["confidence"], "job_relevance": competency_scores["job_relevance"]}) candidate_report = {"candidate_id": "12345", "role": metadata["role"], "competency_scores": competency_scores, "final_score": final_candidate_score, "recommendation": "advance" if final_candidate_score >= 0.75 else "review"} save_to_recruiter_dashboard(candidate_report)
This is where the black box becomes operational. The score may not technically “reject” the candidate. The company may say the tool only supports human judgment, but in early stage hiring, support can become gatekeeping very quickly.
If a recruiter has 3,000 applicants and a dashboard ranks them, the ranking shapes reality. If the system recommends “advance” for some candidates and “review” or “do not prioritize” for others, then the model isn’t sitting politely in the corner offering vibes. It’s influencing who gets seen. That is power, the danger is that by the time the score reaches the dashboard, all the earlier uncertainty has been laundered out.
The recruiter does not see: “This candidate paused frequently, possibly because of anxiety, disability, translation, poor internet connection, or careful thinking.”
They see: “Confidence: below benchmark.”
That is how the black box gets even bigger. Each step compresses context until the final output looks cleaner than the reality that produced it.
Failure at this stage: The Dashboard Makes Uncertainty Look Like Objectivity
Dashboards in this context are dangerous as they make judgment look finished, A number feels final and a ranking feels rational. A recommendation feels like expertise, but if the inputs were ambiguous and the transformations were biased, then the dashboard isn’t revealing truth. It’s displaying processed uncertainty.
The recruiter may trust the score because it looks official. The hiring manager may trust the recruiter because they assume the screening process worked. The company may trust the vendor because the vendor has compliance language. The candidate, meanwhile, never gets to see where the system misunderstood them or how they can improve if they even decide to apply to the same company again.
That is the real black box problem: It’s not just that the model is hard to interpret, it’s that the entire pipeline creates distance between the candidate and the decision.
The Feedback Loop: How the Black Box Gets Bigger Over Time
But the scariest part isn’t even one bad score. It’s the feedback loop. Imagine the company mostly advances candidates who score high on the model. Those candidates then become the “successful” hiring pool. Future models may learn from those patterns based on the amount the data is retained. Over time, the system can keep rewarding the same communication styles, same speech rhythms, same performance behaviors, and same polished interview personas.
hired_candidates = get_candidates_who_were_hired()
performance_reviews = get_performance_data(hired_candidates)
training_data = merge(candidate_features, hiring_outcomes, performance_reviews)
updated_model = retrain_model(training_data)
This looks like improvement, when it may actually it’s bias compounding.
If the original system filtered out qualified candidates with disabilities, anxiety, different speech patterns, or nontraditional communication styles, those candidates never enter the success dataset. The model cannot learn from people it already excluded.
That is the algorithmic version of “you need experience to get experience.”
The system rewards the people who survived the system, then uses their survival as proof that the system works. Very Black Mirror, and “we value diversity” in 12 point font under a stock photo of seven people pointing at a glass wall.
The Core Ethical Problem
The pipeline fails because it can’t contain the growing issues it creates.
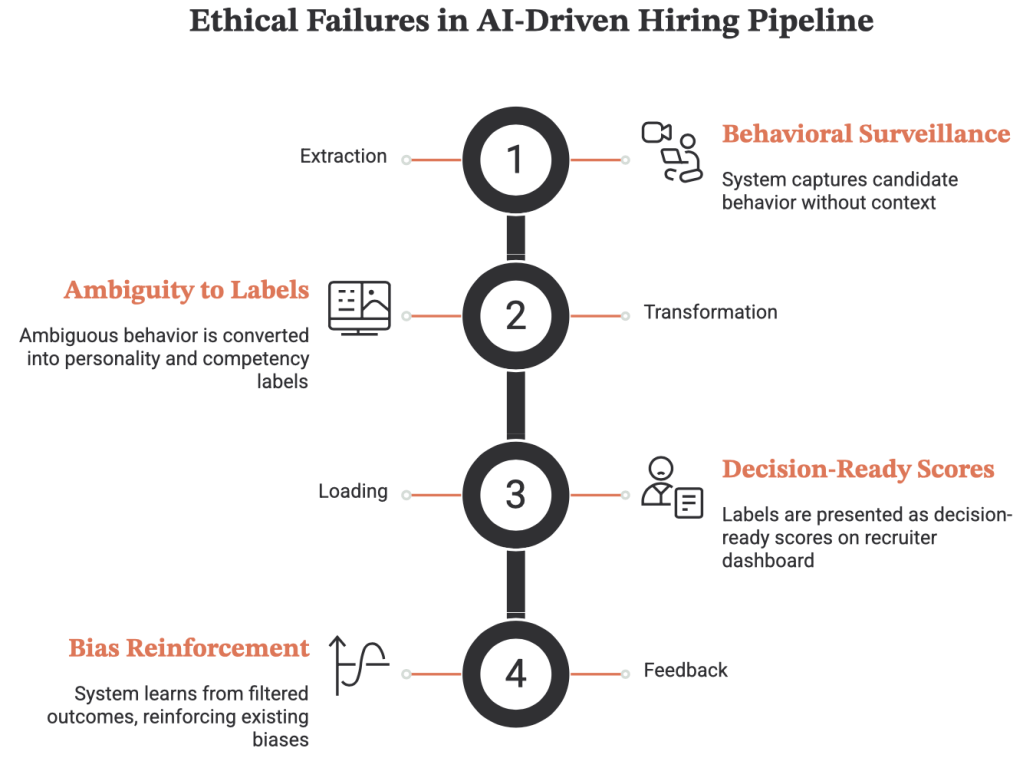
- At extraction: it captures behavior without context.
- At transformation: it turns ambiguous behavior into personality and competency labels.
- At loading: it presents those labels as decision ready scores.
- At feedback: it learns from its own filtered outcomes and may reinforce the patterns it already preferred.
That’s how a black box becomes a bigger black box. Not because one evil coder wrote “be biased” into the code. Bias rarely works that cartoonishly. The issue is more ordinary and more dangerous: a chain of small technical decisions, each one presented as reasonable, can produce a system that quietly penalizes people for being human in the wrong format.
A Better Version of the Pipeline:
A more ethical hiring pipeline would look different. It would minimize behavioral surveillance, focus on job relevant work samples, and would provide accommodations by default. It’d make scoring rubrics visible, test for adverse impact, allow candidates to appeal or request human review and would validate scores against actual job performance, not just interview polish.
The better question is not: “How do we score the candidate’s face, voice, pauses, tone, and rhythm?”
The better question is: “What evidence actually shows this person can do the job?”
